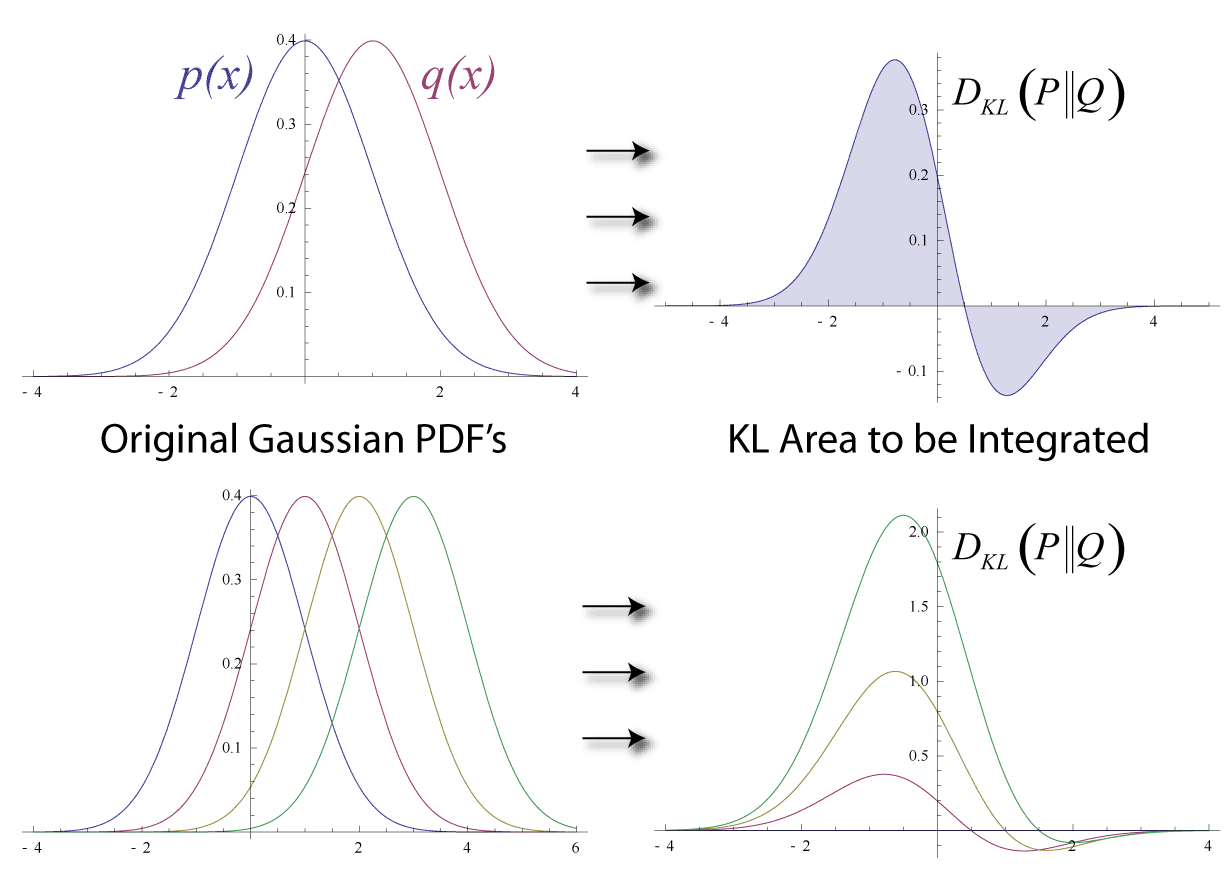
DKL(p∥q)=DKL(q∥p). 거리인데 비대칭이다. 게다가 삼각부등식도 만족하지 않는다. 위상수학에서 배운 거리 공간의 세 공리 — 양수성, 대칭성, 삼각부등식 — 중 두 개를 위반한다. 그렇다면 KL 발산은 "거리"라고 부를 수 있는가?
그런데 이상한 일이 있다. KL 발산은 거리의 자격이 없음에도 불구하고, 실제로는 거리보다 더 많이 쓰인다. 기계학습에서 손실 함수로, 변분추론에서 최적화 목표로, 강화학습에서 정책 간의 차이 측정으로, 정보이론에서 채널 용량 계산에 — KL 발산은 어디에나 있다. 거리 함수의 공리를 만족하지 못하는 것이 "결함"이 아니라 오히려 "특징"이라면?
더 근본적인 질문을 해보자. 비대칭이 물리적으로 의미가 있는 상황이 있는가? 있다. "p가 참인데 q로 근사하는 것"과 "q가 참인데 p로 근사하는 것"은 질적으로 다른 행위다. 정규분포로 이중봉 분포를 근사하면 한쪽 봉우리를 잃지만, 이중봉 분포로 정규분포를 근사하면 없는 봉우리를 만들어낸다. 이 두 오류는 본질적으로 다르며, 비대칭인 발산만이 이 차이를 포착할 수 있다.
패턴
발산의 비대칭은 거시적으로는 눈에 띄지만, 미시적으로는 사라진다. 이것이 핵심 관찰이다. D(p∥q)를 q=p 근방에서 테일러 전개하면:
D(p∥p+δ)=21gijδiδj+O(δ3)
2차 항까지는 δ에 대해 대칭이다. 즉 두 점이 충분히 가까우면 D(p∥q)≈D(q∥p)이다. 그리고 이 2차 항의 계수 gij가 바로 리만 계량이다. KL 발산의 경우 이 계량은 피셔 정보행렬과 일치한다.
발산이 리만 계량을 "유도한다"는 이 사실은 심오한 의미를 갖는다. 비대칭적이고 대역적인(global) 발산이, 국소적(local)으로는 대칭적인 리만 기하학을 낳는다. 마치 지구의 표면이 전체적으로는 곡면이지만 충분히 작은 영역에서는 평면처럼 보이는 것과 같다. 발산은 "먼 곳의 기하학"이고, 리만 계량은 "가까운 곳의 기하학"이다.
발산의 비대칭은 3차 이상의 항에서 나타나며, 이것이 바로 이전 장에서 만난 큐빅 텐서C와 연결된다. 발산의 비대칭 정도가 쌍대 접속 사이의 차이를 결정하는 것이다. 대칭적 발산(예: 유클리드 거리의 제곱)에서는 큐빅 텐서가 0이고, 접속은 레비-치비타 하나뿐이다.
정리 (일반화된 피타고라스 정리)
쌍대 평탄 공간에서 놀라운 정리가 성립한다. 세 점 p, q, r이 있고, q가 ∇-측지적 부분매니폴드 M 위의 점이며 p에서 M으로의 ∇∗-사영이라 하자. 그러면:
D(p∥r)=D(p∥q)+D(q∥r),∀r∈M
이것은 유클리드 기하의 피타고라스 정리 ∣pr∣2=∣pq∣2+∣qr∣2의 정보기하학적 일반화다. "거리의 제곱"이 "발산"으로, "직교"가 "쌍대 측지선의 직교"로 대체된 것이다. 보통의 피타고라스 정리가 직각삼각형에서만 성립하듯, 일반화된 피타고라스 정리도 ∇-측지선과 ∇∗-측지선이 만나는 “쌍대 직교” 조건이 필요하다.
이 정리의 가장 아름다운 응용은 EM 알고리즘의 기하학적 해석이다. EM 알고리즘의 E-단계는 m-사영이고, M-단계는 e-사영이다. 각 단계에서 피타고라스 정리가 적용되므로, 발산은 매 단계마다 반드시 감소한다. EM 알고리즘의 수렴성이 기하학적 필연인 것이다.
변분추론(variational inference)도 같은 틀로 이해된다. 다루기 쉬운 분포족 Q 위에서 참 사후분포 p에 가장 가까운 점을 찾는 것 — 이것이 e-사영(reverse KL 최소화)이다. 블라후트-아리모토 알고리즘, 미러 디센트 등 정보이론과 최적화의 핵심 알고리즘들이 모두 이 교대 사영의 틀로 통합된다.
정의
발산 (비대칭 거리 / Asymmetric Distance, D(p∥q)) — 두 점 사이의 “방향 있는 떨어짐”. 세 가지 조건을 만족한다: (1) D(p∥q)≥0, (2) D(p∥q)=0⟺p=q, (3) q=p 근방에서 D(p∥p+δ)=21gijδiδj+O(δ3)으로, 양정치 이차형식을 유도. 대칭성과 삼각부등식은 요구하지 않는다. 거리보다 약한 조건이지만, 리만 계량을 유도하기에는 충분하다.
브레그만 발산 (볼록함수가 만드는 비대칭 거리 / Convex Gap Distance) — 볼록함수 ϕ에 대해 Dϕ(p∥q)=ϕ(p)−ϕ(q)−⟨∇ϕ(q),p−q⟩으로 정의. 기하학적으로는 q에서의 접선과 p에서의 함수값 사이의 간격이다. 볼록함수의 그래프는 항상 접선 위에 있으므로 Dϕ≥0이다. ϕ(x)=∑xilogxi이면 KL 발산, ϕ(x)=∥x∥2이면 유클리드 거리의 제곱. 쌍대 평탄 공간에서의 발산은 반드시 브레그만 발산이다.
사영 (가장 가까운 점 찾기 / Nearest Point Finder, Π) — 부분매니폴드 M 위에서 주어진 점 p로부터 발산을 최소화하는 점 q∗=argminq∈MD(p∥q). 발산이 비대칭이므로 argminD(p∥⋅)와 argminD(⋅∥p)는 일반적으로 다른 점을 준다. 이 구별이 m-사영과 e-사영의 기원이다.
m-사영 / e-사영 (합의 사영 / 곱의 사영) — m-사영은 argminq∈MD(p∥q)로, 사영점과 원래 점을 잇는 e-측지선이 M에 직교한다. e-사영은 argminq∈MD(q∥p)로, m-측지선이 M에 직교한다. EM 알고리즘에서 E-단계는 m-사영, M-단계는 e-사영이다. 변분추론에서 ELBO 최대화는 e-사영에 해당한다.
핵심 인물과 일화
솔로몬 쿨백 (Solomon Kullback, 1907–1994) & 리처드 라이블러 (Richard Leibler, 1914–2003)
KL 발산의 탄생 배경은 순수 수학이 아니라 암호분석이다. 쿨백과 라이블러는 모두 미국 국가안보국(NSA)의 전신인 육군 신호정보국(SIS)에서 일했다. 쿨백은 제2차 세계대전 기간 일본 외교 암호 해독에 참여한 인물이다.
1951년, 두 사람은 Annals of Mathematical Statistics에 "두 가설의 판별에 관한 정보와 충분성(On Information and Sufficiency)"이라는 논문을 발표한다. 핵심 질문은 이것이었다: 두 확률분포 p와 q가 주어졌을 때, 관측 데이터를 통해 이 둘을 얼마나 잘 구별할 수 있는가?
그 답으로 제시된 것이 DKL(p∥q)=∑xp(x)logq(x)p(x)이다. 이 양은 "p가 참일 때, q를 참이라고 잘못 가정하면 평균적으로 얼마나 많은 정보를 잃는가"를 측정한다.
쿨백과 라이블러 자신도 이것이 비대칭이라는 것을 알고 있었다 — D(p∥q)=D(q∥p). 이 비대칭은 우연이 아니다. "p가 참인데 q라고 착각하는 것"과 "q가 참인데 p라고 착각하는 것"은 질적으로 다른 실수이기 때문이다. 이 비대칭이야말로 KL 발산이 "거리"가 아닌 "발산"인 이유이며, 동시에 정보기하학에서 쌍대 구조가 나타나는 근본적 원인이다.
레프 브레그만 (Lev M. Bregman, 1941–)
KL 발산은 확률분포에 특화된 양이다. 이것을 더 일반적인 틀로 확장한 사람이 소련의 수학자 레프 브레그만이다.
1967년, 브레그만은 볼록 최적화 문제를 연구하다가 다음을 관찰한다: 임의의 볼록함수 ϕ에 대해, Dϕ(p∥q)=ϕ(p)−ϕ(q)−⟨∇ϕ(q),p−q⟩ — 즉 함수값과 접선의 차이 — 로 발산을 정의할 수 있다. ϕ(x)=∑xilogxi로 잡으면 KL 발산이 나오고, ϕ(x)=∥x∥2으로 잡으면 보통의 유클리드 거리의 제곱이 나온다.
브레그만 발산은 정보기하학의 핵심 도구가 되었다. 쌍대 평탄 공간에서의 발산은 항상 브레그만 발산이며, 이것이 자연스러운 피타고라스 정리를 만족한다는 것이 아마리의 이론에 의해 밝혀진다.
시각화 아이디어
정보기하학적 피타고라스 정리: 확률 심플렉스 위에서 e-사영과 m-사영, 발산들 사이의 피타고라스 관계